LLM Boss
Compare frontier LLMs side-by-side on real benchmarks
Table of contents
What is LLM Boss?
LLM Boss is an independent resource that tracks how the latest frontier, state-of-the-art large language models perform on the benchmarks the field actually uses. Instead of wading through launch-day marketing, you pick any two models for a head-to-head and see how they stack up side by side — across agentic coding, terminal and computer use, tool orchestration, web search, long-context and graduate-level reasoning, visual understanding and multilingual knowledge. Every number is sourced from a model's published system card or an independent leaderboard, with the original source linked on each benchmark page.
Key Features
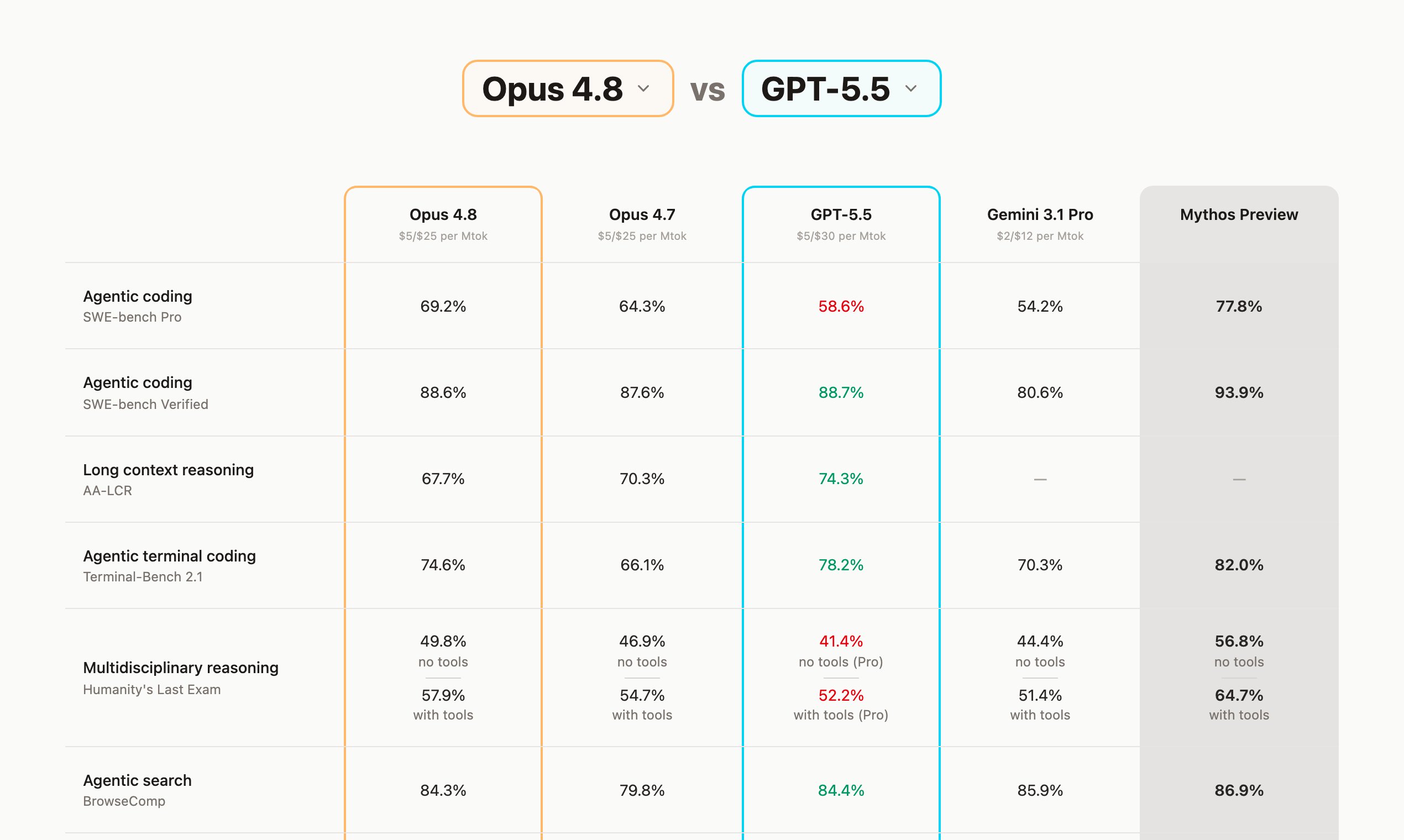
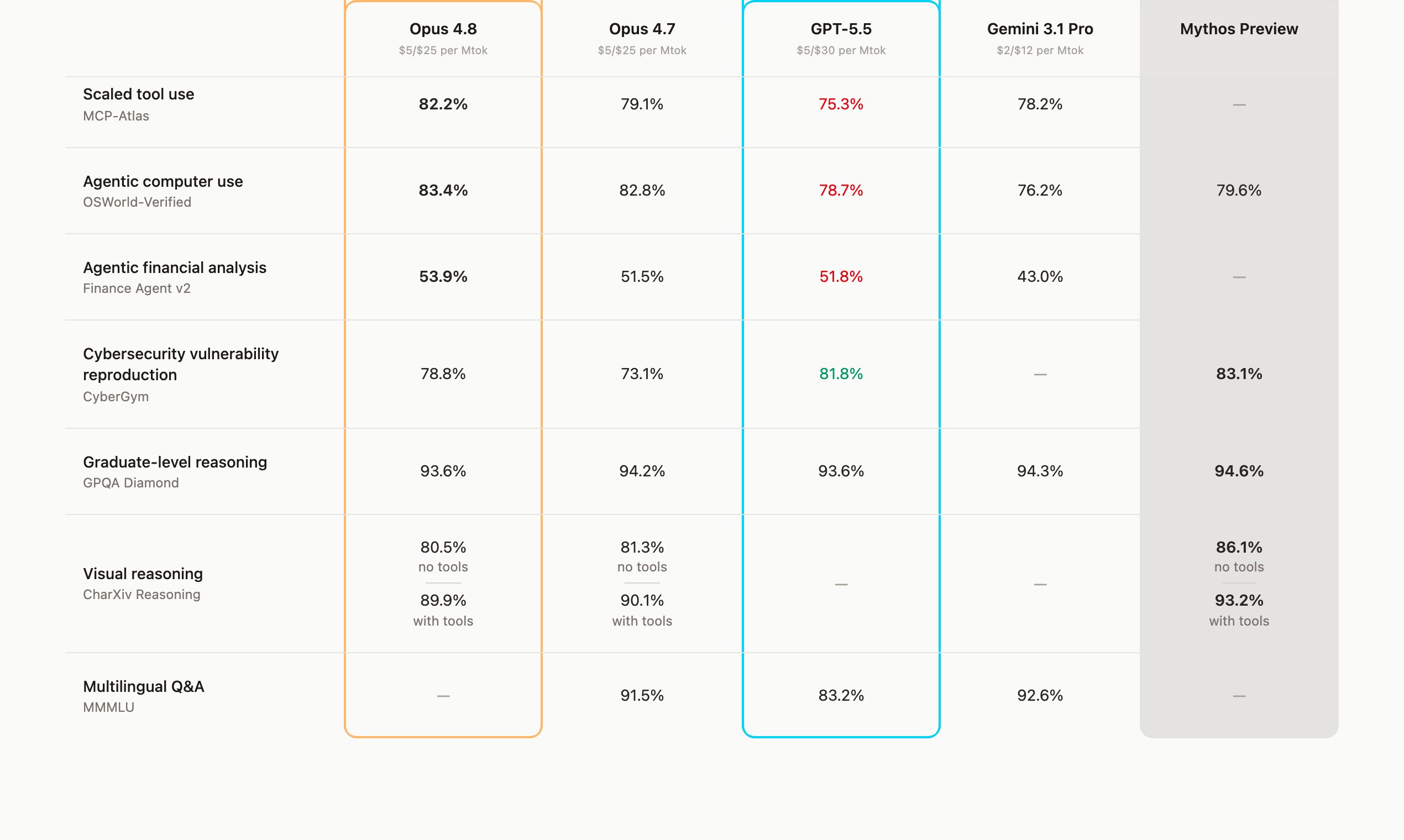
- Head-to-head comparison: Pick any two models — the baseline shown in orange, the challenger in cyan — and read benchmark-by-benchmark wins and losses at a glance.
- Live comparison table: See every tracked frontier model (Opus 4.8, Opus 4.7, GPT-5.5, Gemini 3.1 Pro, Mythos Preview) across more than a dozen evaluations in one view.
- Per-benchmark pages: Dedicated pages for SWE-bench Pro and Verified, Terminal-Bench, AA-LCR, Humanity's Last Exam, BrowseComp, MCP-Atlas, OSWorld-Verified, Finance Agent, CyberGym, GPQA Diamond, CharXiv and MMMLU.
- Sourced, verified data: Each figure links to its official system card or an independent leaderboard such as Artificial Analysis or Scale's SEAL evaluations.
- Tools vs. no-tools splits: Results distinguish scores reported with and without tools, so comparisons stay fair.
- Pricing in context: Token pricing ($ per Mtok) is shown right alongside capability scores.
- Blog & glossary: Benchmark explainers and buying guides, including how to choose and evaluate an LLM and why benchmarks saturate.
Who Can Benefit from LLM Boss
- Engineers & developers: Those choosing a model for agentic coding, tool use, or terminal workflows and want capability data, not hype.
- Technical buyers: Decision-makers weighing models on both cost and capability before committing budget.
- AI researchers & analysts: People tracking frontier benchmark progress and how new releases shift the leaderboard.
- Product teams: Builders evaluating which model best fits a specific workload or feature.
- Anyone comparing models objectively: Readers who want to cut through marketing claims with side-by-side, sourced numbers.
What Makes LLM Boss Unique
- Independent and source-linked: Not tied to any lab — every score links back to its origin so you can verify it yourself.
- Head-to-head framing: An orange baseline versus a cyan challenger, with green and red indicators showing where the challenger wins or trails.
- Workload-oriented axes: Benchmarks grouped by real tasks (coding, agentic, reasoning, multilingual) rather than a single vanity score.
- Honest about gaps: When a lab does not report a benchmark, the cell is left blank ("—") rather than estimated.
- Performance and price together: Token cost sits next to capability, so the cheapest-that-works model is easy to spot.
Pros
- Transparent sourcing: Every figure links to a system card or independent leaderboard, making numbers easy to trust and verify.
- Genuinely comparable: Uses each model's strongest publicly-reported configuration and notes tools vs. no-tools, keeping matchups fair.
- Fast side-by-side: Pick any two models and immediately see the wins and losses, benchmark by benchmark.
- Free and frictionless: Fully accessible with no signup or account required.
- Benchmarks that matter: Focuses on the agentic coding, tool use and computer-use evals engineers actually care about.
Cons
- Limited model roster: Only a handful of frontier models are tracked, so niche or open-source models may be missing.
- Depends on labs publishing: Benchmarks a lab doesn't report show up as blank cells rather than estimates.
- No data export or API: It's a comparison reference, not a programmatic dataset you can pull into your own tools.
- Numbers can lag: Figures only update as new system cards and leaderboard results land.
Links
Summary
LLM Boss is a clean, independent reference for comparing frontier LLMs on the benchmarks that matter. Instead of wading through launch-day marketing, you pick two models and see exactly how they stack up — benchmark by benchmark, with every number linked to its source and token pricing shown alongside. It's a fast, honest way for engineers and buyers to choose the right model for their workload.