This product was not featured by Product Hunt yet. It will not be visible on their landing page and won't be ranked (cannot win product of the day regardless of upvotes).
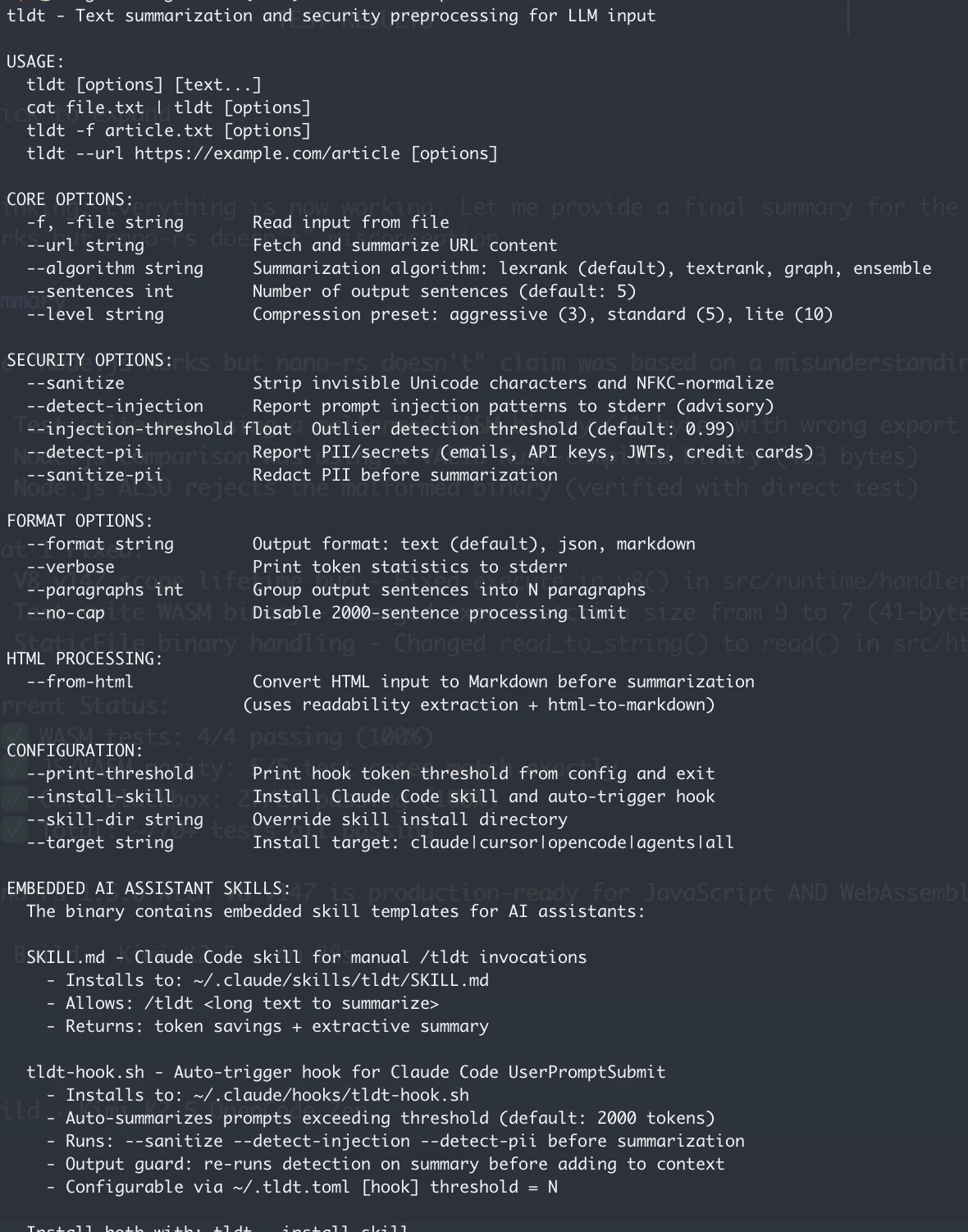
Too Long; Didn't Tokenize (tl;dt) is a CLI and library that uses machine learning to summarize long texts with context. It targets API calls, document uploads and crawled sites with excess tokens, prompt injection, side instructions. - LexRank and TextRank - OWASP LLM Top 10 support - Unicode confusables protection - Converts from HTML to markdown - Text sanitization - PII and API Keys cleaning - No API keys required - A Go Library for agents that call AI APIs directly - A skill for coding
This is a rewrite of a project of mine that used LexRank (https://arxiv.org/abs/1109.2128) to summarize long texts. Initially as an API it became a command line that I used to index data into search engines and general data manipulation. With the advent of LLM many tasks that could be done locally with machine learning algorithms were delegated to models, increasing cost and data leak risk.
I've expanded tl;dt with TextRank and other protections I normally used to make it safe for people to use agentic coding and agents in general to build workflows including Unicode Confusables filtering, prompt injection detection, HTML to Markdown conversion and sanitization, along with better control on output size to maintain proper context.
Also added a simple skill to support agentic coding. It sits close to rtk and caveman in terms of token saving but it focus on keeping the context of the summarized input intact.
Cheers !
No comment highlights available yet. Please check back later!
About tldt — Too Long, Didn't Tokenize on Product Hunt
“Protect your data and agents while saving tokens”
tldt — Too Long, Didn't Tokenize was submitted on Product Hunt and earned 1 upvotes and 1 comments, placing #113 on the daily leaderboard. Too Long; Didn't Tokenize (tl;dt) is a CLI and library that uses machine learning to summarize long texts with context. It targets API calls, document uploads and crawled sites with excess tokens, prompt injection, side instructions. - LexRank and TextRank - OWASP LLM Top 10 support - Unicode confusables protection - Converts from HTML to markdown - Text sanitization - PII and API Keys cleaning - No API keys required - A Go Library for agents that call AI APIs directly - A skill for coding
tldt — Too Long, Didn't Tokenize was featured in Artificial Intelligence (473.1k followers), GitHub (41.3k followers), Search (18.1k followers) and Data Science (3.8k followers) on Product Hunt. Together, these topics include over 133.5k products, making this a competitive space to launch in.
Who hunted tldt — Too Long, Didn't Tokenize?
tldt — Too Long, Didn't Tokenize was hunted by gleicon. A “hunter” on Product Hunt is the community member who submits a product to the platform — uploading the images, the link, and tagging the makers behind it. Hunters typically write the first comment explaining why a product is worth attention, and their followers are notified the moment they post. Around 79% of featured launches on Product Hunt are self-hunted by their makers, but a well-known hunter still acts as a signal of quality to the rest of the community. See the full all-time top hunters leaderboard to discover who is shaping the Product Hunt ecosystem.
Want to see how tldt — Too Long, Didn't Tokenize stacked up against nearby launches in real time? Check out the live launch dashboard for upvote speed charts, proximity comparisons, and more analytics.
 gleicon
gleicon