Qwen team from Alibaba presents the Qwen 2.5 series: Qwen2.5-Max (large-scale MoE), Qwen2.5-VL (vision-language), and Qwen2.5-1M (long-context). This represents a significant step forward.
Hey everyone! The Qwen team from Alibaba Cloud recently launched the latest Qwen 2.5 series, featuring some powerful new AI models.
Key Highlights:
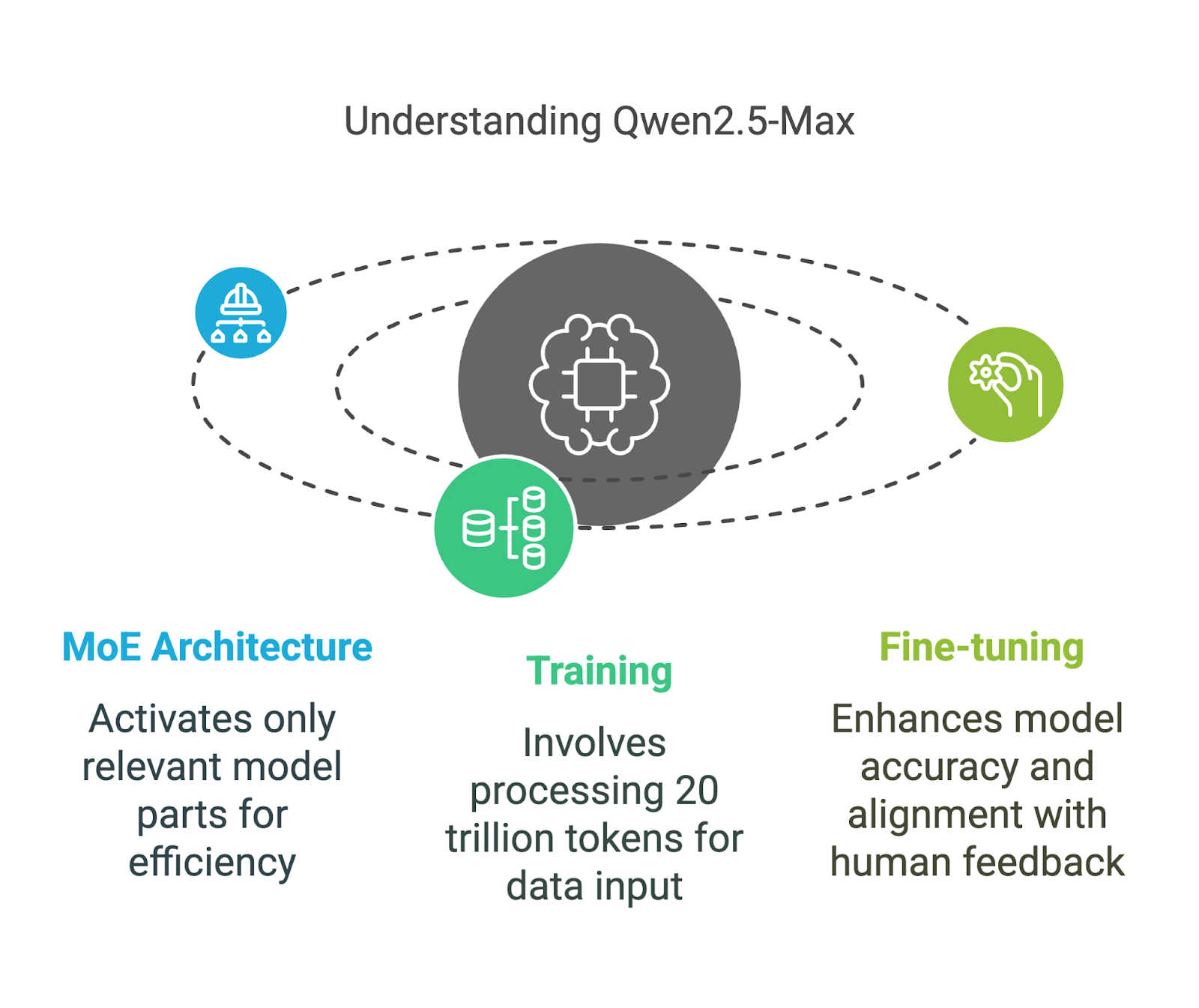
🚀 MoE Power (Max): Qwen2.5-Max leverages a Mixture-of-Experts architecture for enhanced intelligence.
🖼️ Advanced Vision-Language (VL): Qwen2.5-VL offers a huge leap in visual understanding and processing.
📖 Long-Context Capability (1M): Qwen2.5-1M tackles extra-long documents and conversations.
🌍 Open-Source Options: Both Qwen2.5-VL and Qwen2.5-1M offer open-source models for the community (See these Models on their Hugging Face).
You can try Qwen 2.5 series model in Qwen Chat: https://chat.qwenlm.ai/
@zac_zuo Your model shows great potential, but it could be even more competitive with other models in this series if you increased the context window size. Expanding this would significantly enhance its capabilities and overall performance.
I particularly like the small Qwen models I can run on my own computer. But this is really great: so much work enterprising individuals can distill smaller models from. And jush have the VL and 1M now available is great!
Glad to see more and more Mixture-of-Expert (MoE) architectures leading the LLM leaderboard! DeepSeek and Qwen is all over the place in my social feed these days! Curious how will Alibaba apply Qwen to its current business portfolio?
I recommend paying attention to Qwen 2.5 from Alibaba, as it is a serious step forward in the world of artificial intelligence. The model received high ratings, which confirms its effectiveness. It will be very interesting to see how it will affect the future of AI development!
That Alibaba launched Qwen 2.5-Max on the first day of the Lunar New Year signals an urgent response to DeepSeek's recent AI breakthroughs.
This large-scale Mixture-of-Expert (MoE) model has been pre-trained on over 20 trillion tokens (!!) and enhanced through Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF).
I mean come on, who doesn't love AI model after AI model coming out in quick succession, there's so many to try now!!
Going to have to dive into this one ASAP before people use up all the server space!
Thanks for hunting Zac!!